Publications & Work in progress
I published in several international journals and also I have some work in progress, you can see more details here or in my Google Scholar page.

Loss Data Analysis: The Maximum Entropy Approach
Operational Risk Assessment is an important tool to mitigate losses. This textbook focuses on loss data analysis using a maximum entropy approach.
This book contains most of the work developed in my Ph.D dissertation.
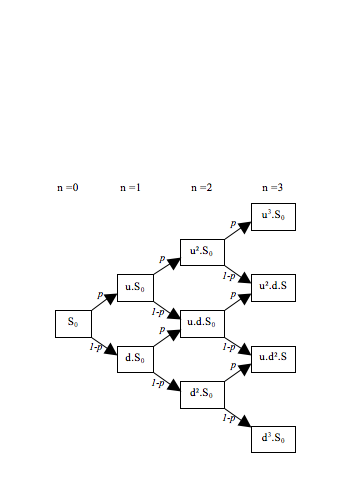
Calibration of short rate term structure models from bid–ask coupon bond prices
Our recent work consists in the use of maximum entropy methods for the calibration of discrete time term structure models from coupon bond prices. Here, we use maxentropic methods to determine the short rates along to a binomial tree to obtain a non-parametric alternative to the Black-Derman-Toy and Ho-Lee models used to price derivatives.
Key words:

Maxentropic and quantitative methods in operational risk modeling
After a while, I finally submitted my PhD thesis. In it, I organised the already published results related with how to apply Maxentropic Methodologies to OP. There, I collected lots of bits and pieces of new ideas that I had lying around (which I hadn’t had the time to publish yet). The potential of the maxent methodologies is varied. This thesis can be extended to solve problems in the area of finance, risk, insurance, and applied statistics (as extreme value theory, clustering, lifetime value calculations), between others applications.
Key words:
A Maximum Entropy Approach to the Loss Data Aggregation Problem
Here, we briefly discuss how the Maxentropic method could be used to capture dependencies between random sums in the last level of aggregation. The results are compared with a standard procedure (the convolution method) in order to proof how the maximum entropy performs easily with less computational effort.
Key words:
[pdf][Presentation][Blog post]
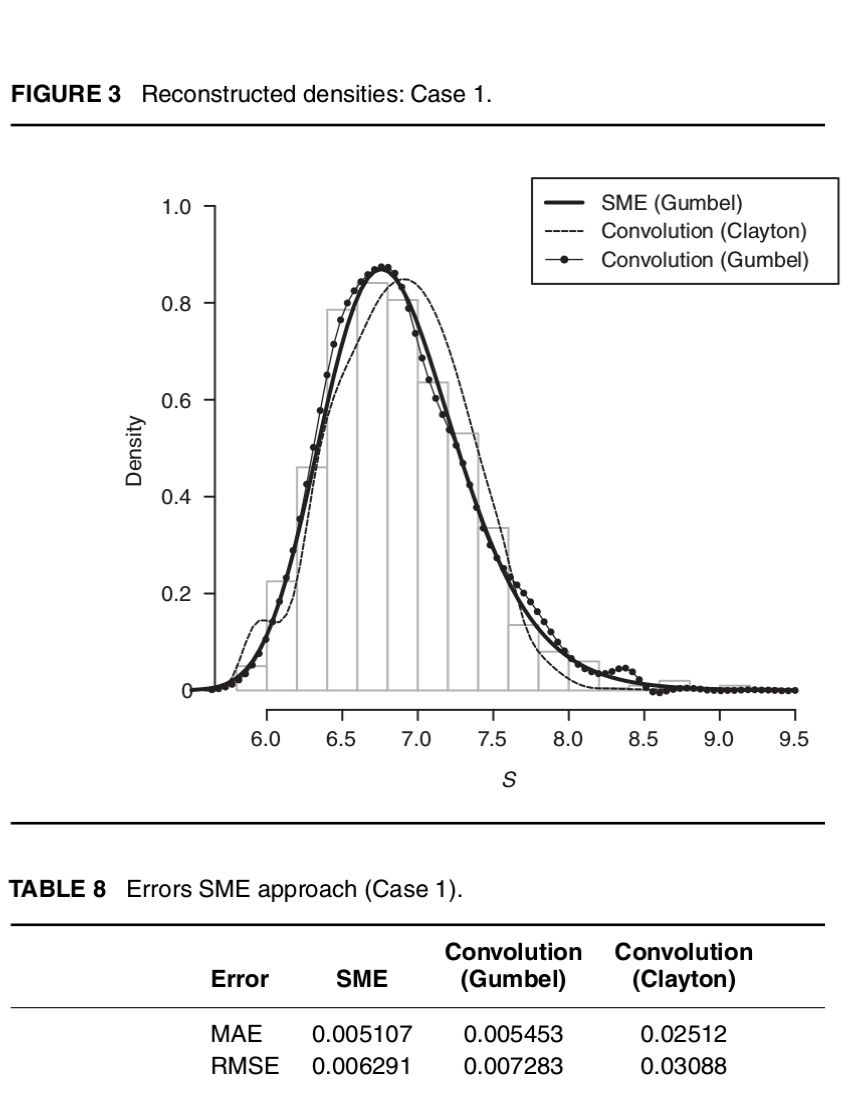
Loss data analysis: Analysis of the sample dependence in density reconstruction by maxentropic methods
At this point, we have concluded that maximum entropy based techniques are rather powerful to determine density distributions in Risk. So, the pending question is: What happen when the data is scarce, as is common in baking?. At this point we know that the maxentropic density depends upon the data used. In this paper, we analyze the variability of the reconstructed densities to examine the impact of this variability on the estimation of \(VaR\) and \(TVaR\), which are favored tool of financial regulators for bank capital adequacy, and extensively used in fields such as insurance and fund management.
Key words:
[pdf][Software][Presentation][Blog post]
Maxentropic Approach to Decompound Aggregate Risk Losses
We extend the methodology that was called decompounding in the paper ‘Two maxentropic approaches to determine the probability density of compound risk losses’ to separate the risk sources and to identify the statistical nature of the frequency and severity through the use of maximum entropy and clustering methods.
Key words:
[pdf][Conference][Presentation][Blog post]
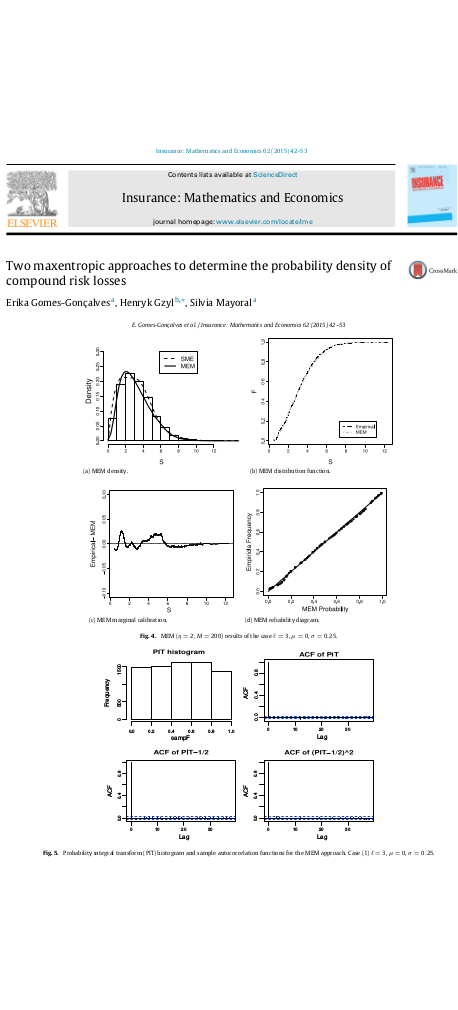
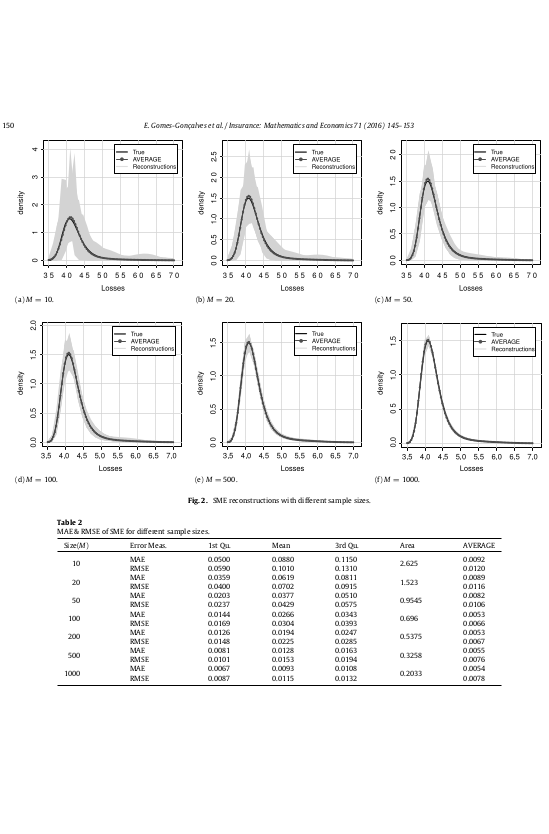
Two maxentropic approaches to determine the probability density of compound risk losses
Here we studied two maxentropic methodologies called Standard Maximum Entropy method (SME) and Maximum Entropy in the Mean method (MEM) to find the density distribution of aggregated loss data using the Laplace transformation as an input. We considered as example a Poisson-LogNormal process. This case was chosen because the closed form of the Laplace transform of a Lognormal is not known and neither its compound sum. Then, to solve this, we considered the numerical form of the Laplace over the simulated data, and we evaluated the results through the use of visualizations and several tests. Additionally, in this paper we made the first attempt to decompose the random sums in its frequency/severity distributions through the use of maxent methodologies. The idea behind this paper is to prove the simplicity and value of the maxent methods for the calculation of the regulatory capital through estimation of Value at Risk (\(VaR\)) and Tail value at risk(\(TVaR\)).
Key words:
[pdf] [Software][Presentation][Blog post]
Density reconstructions with errors in the data
We examined two possible ways of deal with sample errors, within the framework of the SME method. The differences between the two approaches lay on the output of these methodologies. One of these methods provided an additional output that worked as an estimator of the additive error.
Key words:
[pdf][Abstract][Blog post]
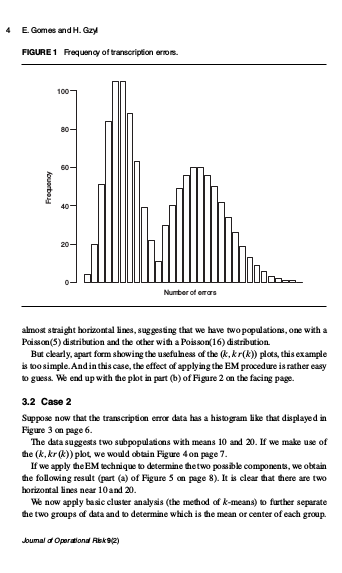
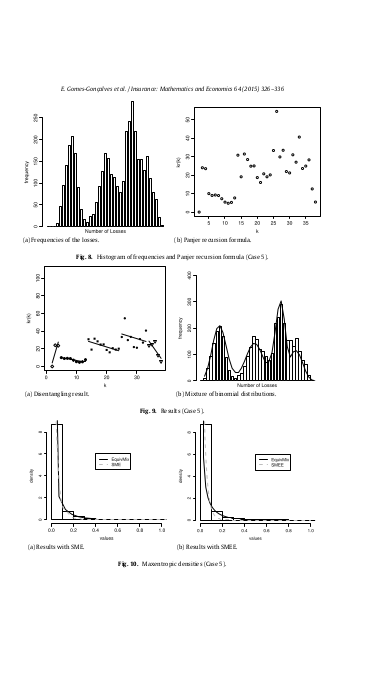
Disentangling frequency models
This is a short paper that pretends to introduce the first step of a procedure that we develop in the paper Maxentropic Approach to Decompound Aggregate Risk Losses. The methodology proposed here, try to solve a problem that is particularly common in firms in the early stages of operational risk data modeling, when the data collection procedure does not distinguish between subpopulations or sources of risk. This methodology that later we call disentangling consists in separate the risk sources and identify the statistical nature of the frequency through the use of models of the type \((a, b, 0)\) and clustering methods like k-means and EM algorithm, when the number of sources of risk is known.
Key words:
[pdf] [Software][Presentation][Blog post]
This website was built using R Markdown, 2017.